基于特征识别的人工智能算法的核心方法论 郝伟 2021/07/21 [TOC]
1. 1 简介
现在机器学习的工具和方法非常多。机器学习方法主要分为有监督和无监督(注:半监督本质上就是两者的组合不单独考虑),但是万变不离其宗,在这么多方法中,基本核心的方法论,尤其是基于特征工程的方法论,都是一样的。
本文主要讨论监督学习,即有预测结果的学习。下面就此方法论进行介绍。为了便于读者理解,在本文中使用性别区分作为示例。
2. 2 机器学习核心流程
2.1. 2.1 特征工程
特征工程就是选择目标的属性进行量化的过程。举例来说,为了区别男女,我们可以用身高作为1个特征,体重作为1个特征,这样就有了两个特征,具体表现为数据表中的两列。
2.2. 2.2 目标值确定
当有了身高和体重以后,我们还需要知道每对身高和体重的性别,这样我们可以得到以下数据:
(Gender,Height,Weight) = (0,156,38)
其中第1个属性为目标值,第2,3个属性分别为身高和体重数据。
2.3. 2.3 数据集
有了这样的定义以后,就需要准备训练数据了,比如:
Gender,Height,Weight
0,156,38
1,155,50
...(省略若干行)...
0,157,48
1,173,69
数据集需要来自实际的测量数据。如果使用模拟数据,那么无法使用的。比如身高和体重的数据,如果随机生成,则根本无法体现出男女的区别。
2.4. 2.4 数据集拆分
为了训练模型,需要将数据集拆分为训练集与测试集,其中:
- 训练集:用于模型训练;
- 测试集:用于测试训练好的模型的性能指标。
一般来说,两个集合的拆分是按行完成的,其中训练集占70%-80%,测试集占20%-30%。
2.5. 2.5 模型选择与训练
准备完数据以后,需要选择合适的模型进行训练。现在的模型有很多,但是基本的使用方法几乎一样,具体分为两步:
第1步:模型初始化,使用特定的参数实例化模型;
第2步:使用训练集数据进行模型训练,甚至连名称都几乎一样地使用 fit。
完成以后,模型就具有了训练能力。
2.6. 2.6 模型预测与评价
使用训练好的模型调用其预测方法,对预测数据进行预测。为了了解模型的性能指标,通常会用 acc, pre, rec 和 f1 进行验证。即使用指定的测试集预测得到预测结果集,再与测试集中的结果部分进行比对。根据比对的结果确认4个指标的能力。
3. 3 经验分享
机器学习的方法论大同小异,真正有价值的包括以下三点:
3.1. 3.1 特征工程
特征工程非常重要,特征定义的好坏直接决定了模型的能力。举例来说,如果仅通过外观特征,如仅身高和体重进行区别,那么是无法正确区别男女的,因为两者有很多重叠部分,并不是决定性的,如下图所示,是1000名男女的身高和体重分布图:
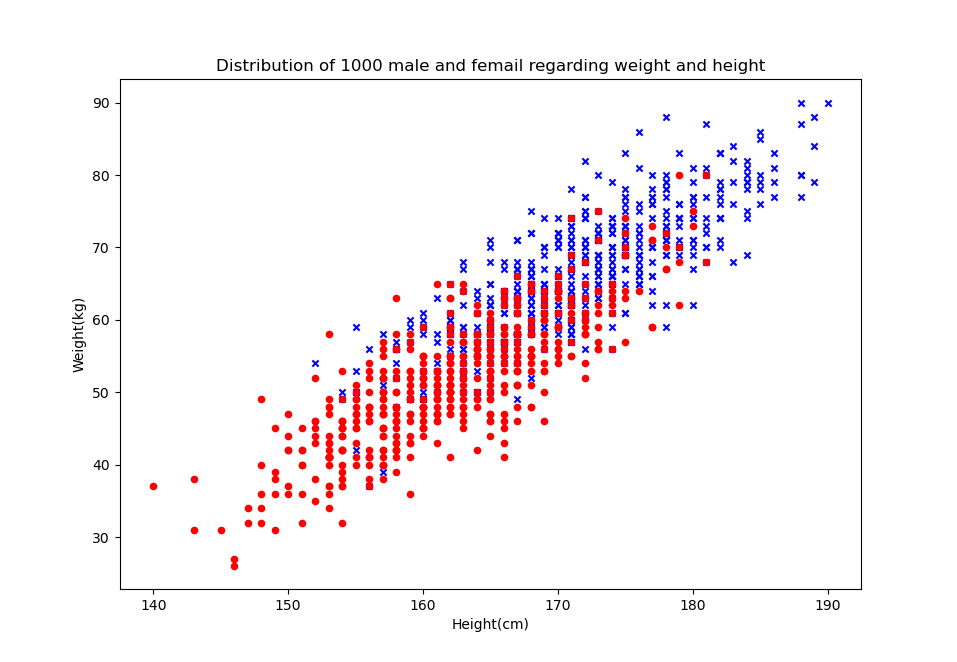 由图上可见,两者有大量的重叠部分,所以自然无法很好地区分,基本根本原因就是特征的维度不够。解决的办法就是再增加一些指标,比如:
由图上可见,两者有大量的重叠部分,所以自然无法很好地区分,基本根本原因就是特征的维度不够。解决的办法就是再增加一些指标,比如:
- 体脂率,即肌肉和脂肪的比例,通常男性比女性要低5%左右;
- 腿长比,即腿与身体的比例,通常女性比例更高;
- 胸腰比,即胸转和腰围的比例,通常女性要明显高于男性。
- 其他
虽然这些特征单一来说,都是不是决定的维度,但是通过添加这些特征联合进行训练,则区别率会大在提高。
顺便再提一下,与维度不足相反的情况是维度过高,即特征太多。特征太多的情况虽然可以解决问题,但是对数据收集和计算量都会造成一定的困难,所以需要减少不必要或使用不大的维度(比如身体数据中体温,男女体温相差不大,而且每个人每天不同时段,不同行为时温差都比较大,所以性别区分能力弱,可以不用考虑),这就是我们常说的降维问题。
3.2. 3.2 数据准备
这是最基本也是最重要的内容。俗话说“巧妇难为无米之炊”,数据就是米,没有数据集再好的模型和算法也能工作。
3.3. 3.3 模型选择
模型相当于做饭的烹饪手法,相同的原料的输出结果差异会很大。模型的选择一方面取决于业务和数据的特性,另一方面取决于模型本身的能力。几乎不存在,一种模型使用所有场景的情况。所以这需要使用人员根据具体情况进行分析和选择。
4. 4 小结
从本质上来,所有的机器学习基本都是这样的方法。但是由于一些方法的某些过程的特殊性,使得过程与上面说的有些不同。比如深度学习,整个神经网络的建立;又如强化学习中的转移矩阵的使用等。