200万条关系导入 郝伟 2021/02/19 [TOC]
1. 简介
在完成了 50万节点插入测试 测试以后,发现关系的插入与节点的插入有所不同,主要包括两点:
- 关系除了自身属性还要包括两个节点的关系;
- 关系中的节点如何进行定位
其中关于第2条,尤其重要,根据之前的测试,发现使用 Where 子句匹配时,需要花费很多时间,是一个需要重要考虑的内容。所以首先进行了关于索引的测试。
2. 索引测试
2.1. 1 使用索引查询节点
以下测试可以看出,使用索引能够有效提高节点的检索速度。
--从322750节点中找到名为郑西的人
MATCH (n:Person{name: "郑西"}) RETURN n LIMIT 25
--建立前:
Started streaming 2 records after 1 ms and completed after 461 ms.
--建立后:
Started streaming 2 records after 2 ms and completed after 2 ms.
--从322750节点中找到名为杨频珍的人
MATCH (n:Person{name: "杨频珍"}) RETURN n LIMIT 25
--建立前:
Started streaming 1 records after 2 ms and completed after 426 ms.
--建立后:
Started streaming 1 records after 2 ms and completed after 3 ms.
--从322750节点中找到名为田轻偷的人
MATCH (n:Person{name: "田轻偷"}) RETURN n LIMIT 25
--建立前:
Started streaming 1 records after 2 ms and completed after 421 ms.
--建立后:
Started streaming 1 records after 2 ms and completed after 3 ms.
--PS. 创建32.3万个索引的用是6ms,平均1ms创建5万多个。
Added 1 index, completed after 6 ms.
2.2. 2 关系插入时的索引对性能的影响
MATCH (a:Person), (b:Person)
WHERE a.name = "谢维娅" AND b.name = "方白生"
CREATE (a)-[f:Friends]->(b)
RETURN a,b
--创建前:
Created 1 relationship, started streaming 1 records after 1078 ms and completed after 1078 ms.
--创建后:
Created 1 relationship, started streaming 1 records after 195 ms and completed after 196 ms.
MATCH (a:Person), (b:Person)
WHERE ID(a) = 159234 AND ID(b) = 326213
CREATE (a)-[f:Friends]->(b)
RETURN a,b
Created 1 relationship, started streaming 1 records after 4 ms and completed after 4 ms.
MATCH (a:Person), (b:Person)
WHERE a.id = 159235 AND b.id = 326213
CREATE (a)-[f:Friends]->(b)
RETURN a,b
--创建前:
Created 1 relationship, started streaming 1 records after 815 ms and completed after 815 ms.
--创建后:
Created 1 relationship, started streaming 1 records after 2 ms and completed after 2 ms.
MATCH (a:Person), (b:Person) WHERE a.id = 159235 AND b.id = 3262141 CREATE (a)-[:Friends]->(b)
2.3. 3 初步结论
通过以上的测试,可以发现以下重要的结论:
- 对于图数据库,索引同样能够加速检索
- 整型比字符串的索引效率更高。
所以,后面关系的插入也同样利用索引进行加速。另外,通过实验还发现 neo4j 需要一定量的内存,至少2G起步,多多益善。
3. 实验设计
核心是编写一个CQL生成函数 string get_cql(string name, int count, int max) 用于生成指定格式的字符串。具体作用就是用于处理图中的节点和关系的表示,其中name就是在输出中方括号内的名称,count决定了节点的数量,id后面的值是随机值,但是小于max。生成的插入关系是链式的,即 节点1--边1-->节点2--边2-->节点3...节点n_1--边n-->节点n 使用 n+1 个节点以生成 n 条关系。
以下是执行不同的参数得到的结果:
get_cql('Frineds', 2, 50000) 得到:
MATCH (n0:Person), (n1:Person) WHERE n0.id=471787 AND n1.id=103795 CREATE (n0)-[:Frineds]->(n1)
get_cql('Frineds', 3, 50000) 得到:
MATCH (n0:Person), (n1:Person), (n2:Person) WHERE n0.id=400454 AND n1.id=228240 AND n2.id=19799 CREATE (n0)-[:Frineds]->(n1)-[:Frineds]->(n2)
get_cql('Frineds', 4, 50000) 得到:
MATCH (n0:Person), (n1:Person), (n2:Person), (n3:Person) WHERE n0.id=115219 AND n1.id=451118 AND n2.id=402292 AND n3.id=25697 CREATE (n0)-[:Coworkers]->(n1)-[:Coworkers]->(n2)-[:Coworkers]->(n3)
get_cql('Frineds', 11, 50000) 得到:
MATCH (n0:Person), (n1:Person), (n2:Person), (n3:Person), (n4:Person), (n5:Person), (n6:Person), (n7:Person), (n8:Person), (n9:Person), (n10:Person) WHERE n0.id=482246 AND n1.id=309116 AND n2.id=173604 AND n3.id=317509 AND n4.id=478207 AND n5.id=233326 AND n6.id=203783 AND n7.id=187576 AND n8.id=265593 AND n9.id=208146 AND n10.id=69812 CREATE (n0)-[:Relatives]->(n1)-[:Relatives]->(n2)-[:Relatives]->(n3)-[:Relatives]->(n4)-[:Relatives]->(n5)-[:Relatives]->(n6)-[:Relatives]->(n7)-[:Relatives]->(n8)-[:Relatives]->(n9)-[:Relatives]->(n10)
4. 50万Friends关系插入测试
本实验是插入50万条 Friends 关系实验,在增加了内存以后非常顺利,一次通过,这是日志文件。
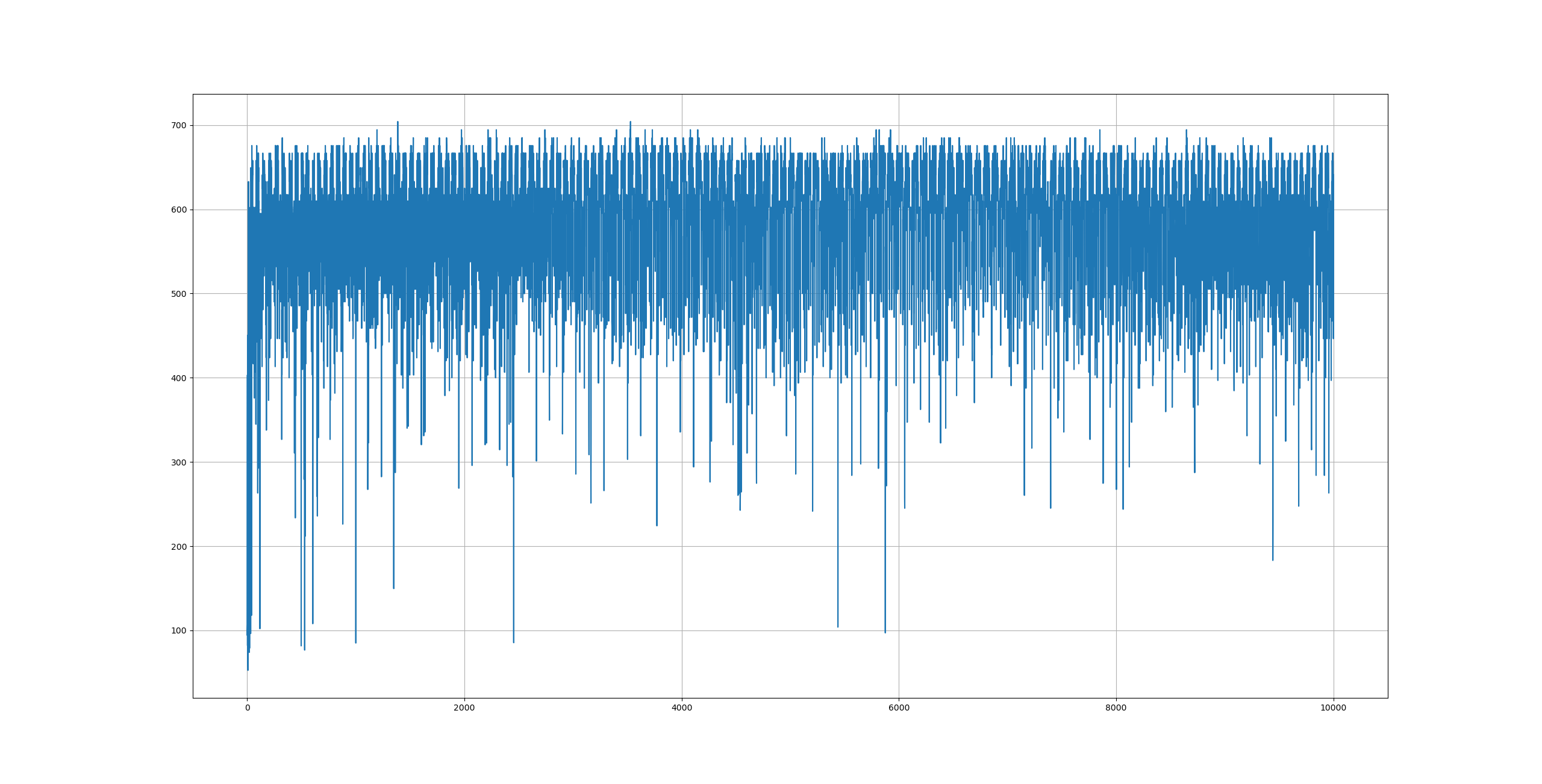
实验开始于 15:05:19,结束于 15:19:44,仅用时14分25秒,平均插入速度为 578边/秒,速度曲线如下所示:
在本次实验完成以后,又添加了三种关系:'Coworkers', 'Relatives', 'Families',每种关系都是50万条。整个过程使用同样的代码,比较顺利完成,具体过程不再细表。
5. 附:实验代码
#coding:utf-8
# 1. 随机生成 50万个节点标签均为Person,包括 name, sex 和 age 三个属性
# 2. 随机生成 200万个关系,包括朋友,同事,同学和亲戚4种关系
from neo4j import GraphDatabase
import random
import time
# id, name, sex(m/f), age(1-100)
# with open('data.txt', 'w', encoding='utf-8') as f:
# f.write('{0},{1},{2},{3}\n'.format(id, name, sex, age))
def create_nodes(tx, cql):
return tx.run(cql)
print('Connecting 121.196.157.14:7687 ...')
driver=GraphDatabase.driver('bolt://121.196.157.14:7687', auth=('neo4j', 'hd7iu2_X@v4u'))
# MATCH (n1:Person), (n2:Person), (n3:Person) WHERE
# a.id = 159235 AND b.id = 326214 AND c.id = 13579
# CREATE (a)-[:Friends]->(b)-[:Friends]->(c)
def get_cql(edge_name, batch_count=51):
cql = 'MATCH '
cql += ', '.join(['(n{0}:Person)'.format(i) for i in range(batch_count)])
cql += ' WHERE '
cql += ' AND '.join(['n{0}.id={1}'.format(i, random.randint(1, maxsize)) for i in range(batch_count)])
cql += ' CREATE '
cql += ('-[:' + edge_name + ']->').join(['(n{0})'.format(i) for i in range(batch_count)])
return cql
# 运行1万次,每次插入50个节点,总计50万个节点
maxsize=500000
total_times = 10000
batch_count = 50
f = open('log.txt', 'w') # 记录日志
print('Connected.')
try:
with driver.session() as session:
print("Begin transctions...")
for edge_name in ['Friends', 'Coworkers', 'Relatives', 'Families']:
print('Begin processing ' + edge_name + ' ...')
for runTimes in range(total_times):
cql = get_cql(edge_name)
start_time=time.time()
session.write_transaction(create_nodes, cql)
end_time=time.time()
total_time=end_time - start_time # 每次插入用时
speed = batch_count / total_time # 插入速度
info = time.strftime("%Y/%m/%d %H:%M:%S", time.localtime()) + ' {0:>5d}: {1:6.3f}s, {2:6.2f} edges/s.'.format(runTimes, total_time, speed)
print(info)
f.write(info + "\n")
except:
pass
f.close()
print('\ndone')