50万节点插入测试 郝伟 2021/02/18 [TOC]
1. 简介
本测试的主要目的是了解neo4j插入50万个节点是否可行,以保证test.json中的42万条数据的顺利导入。
2. 测试方法
本测试需要插入50万个节点,节点的标签为 Person,共有id, name, sex 和 age 4个属性。其中:
- id 为顺序编号,从1开始至500000;
- name 为中文人名,使用 get_name() 函数随机生成;
- sex 表示性别只有 'm' 和 'f' 两个值分别表示男女;
- age 表示年龄取值范围为 1-99。
以下是10条示例数据:
0,邱边,m,50
1,杨喜老,f,6
2,文衣瑞,f,82
3,蒋孩约,m,96
4,董常,m,13
5,袁罗最,f,7
6,袁友怿,m,78
7,方找迈,m,38
8,钱感说,f,25
9,贾威,m,53
由于50万个Person节点的数据量比较大,所以如果每次插入1个节点则需要每次连接和判断的操作过于频繁,消耗多余的时间。所以,代码中以50个为一组,建立一条CQL语句,其内容为 CREATE (n1), (n2), ..., (n50) ,然后一次执行。
3. 实验1:50万节点插入
3.1. 第1次实验(失败:未知原因)
代码经调试正常,从 17:03 运行至 17:45 速度越来越慢,几乎每个执行都要几秒,最后服务器卡死,只好重启服务器再次执行。
cpu:1核 Intel(R) Xeon(R) CPU E5-2630 @ 2.30GHz 内存:4g 硬盘:16g
3.2. 第2次实验(失败:内存不足)
cpu:1核 Intel(R) Xeon(R) CPU E5-2630 @ 2.30GHz 内存:4g 硬盘:16g
在第1次执行失败后,重新修改了代码添加了计时和日志内容。但是最终执行仍然失败,这是日志文件。 有两点发现:
3.2.1. 执行速度越来越慢
执行速度从200-400节点/秒,降低到最后的0.19节点/秒。然后编写以下代码分析速度,得到节点插入的速度曲线如下所示:
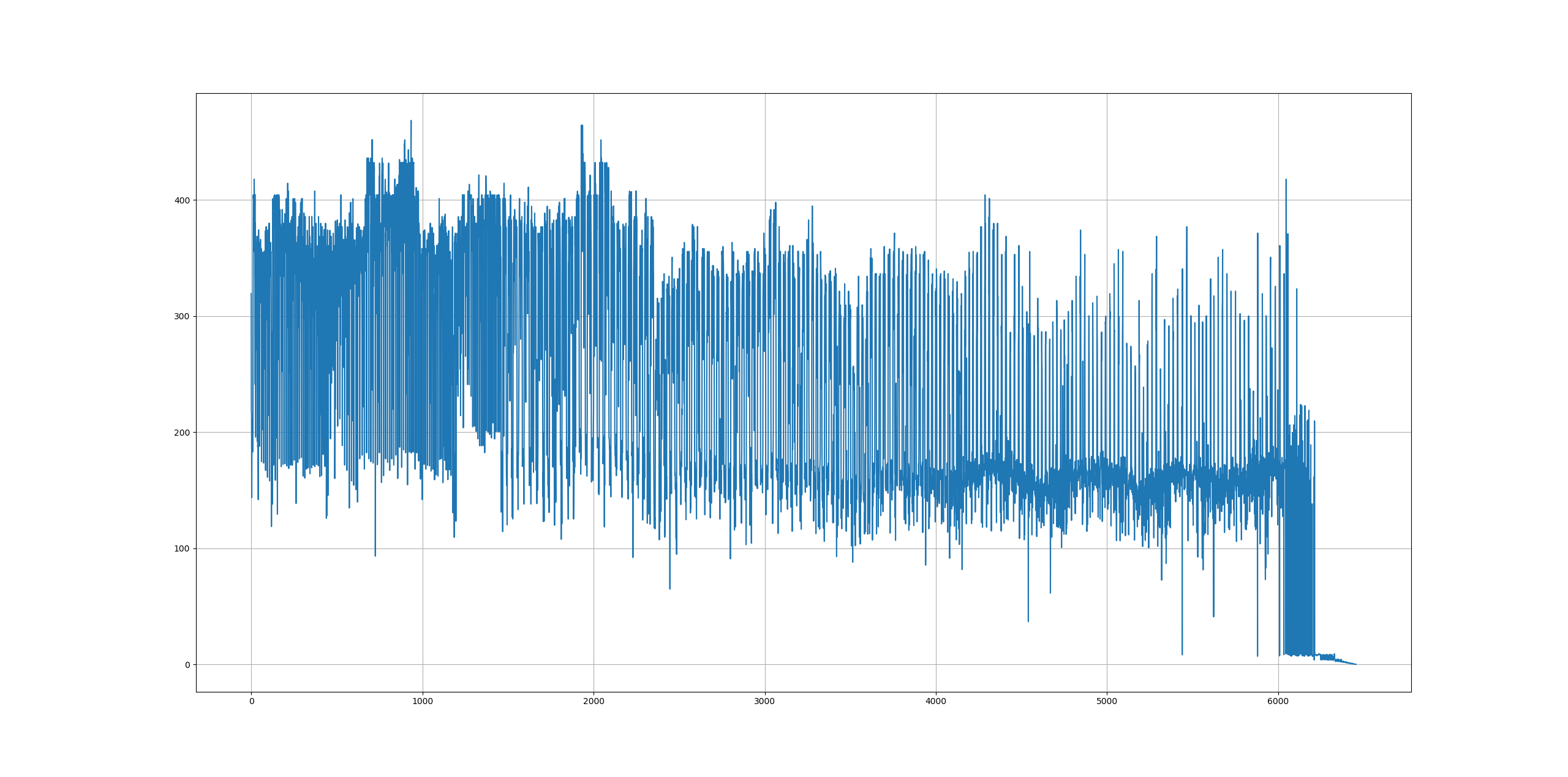
从图像上来看,我们有以下两点结论:
- 插入速度不稳定波动较大;
- 速度越来越慢下降明显。
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
def read_log(logpath):
with open(logpath, 'r') as f:
lines = f.readlines()
return lines
logs=read_log('log.txt')
speeds=[]
for line in logs:
if len(line) == 0:
break
speed=line[36:44].strip()
speeds.append(float(speed))
plt.grid()
plt.plot(range(len(speeds)), speeds)
plt.show()
3.2.2. 在第6454次执行后程序出错
通过阅读日志,发现最后一次执行为6454(即在插入32.275万个节点后)出错,同时报出以下错误信息:
Transaction failed and will be retried in 1.021864417956132s (There is not enough memory to perform the current task. Please try increasing 'dbms.memory.heap.max_size' in the neo4j configuration (normally in 'conf/neo4j.conf' or, if you you are using Neo4j Desktop, found through the user interface) or if you are running an embedded installation increase the heap by using '-Xmx' command line flag, and then restart the database.)
Traceback (most recent call last):
File "neo4j_creation_test.py", line 51, in <module>
session.write_transaction(create_nodes, cql)
File "C:\ProgramData\Anaconda3\lib\site-packages\neo4j\work\simple.py", line 403, in write_transaction
return self._run_transaction(WRITE_ACCESS, transaction_function, *args, **kwargs)
File "C:\ProgramData\Anaconda3\lib\site-packages\neo4j\work\simple.py", line 334, in _run_transaction
raise errors[-1]
File "C:\ProgramData\Anaconda3\lib\site-packages\neo4j\work\simple.py", line 309, in _run_transaction
result = transaction_function(tx, *args, **kwargs)
File "neo4j_creation_test.py", line 30, in create_nodes
return tx.run(cql)
File "C:\ProgramData\Anaconda3\lib\site-packages\neo4j\work\transaction.py", line 118, in run
result._tx_ready_run(query, parameters, **kwparameters)
File "C:\ProgramData\Anaconda3\lib\site-packages\neo4j\work\result.py", line 57, in _tx_ready_run
self._run(query, parameters, None, None, None, **kwparameters)
File "C:\ProgramData\Anaconda3\lib\site-packages\neo4j\work\result.py", line 101, in _run
self._attach()
File "C:\ProgramData\Anaconda3\lib\site-packages\neo4j\work\result.py", line 202, in _attach
self._connection.fetch_message()
File "C:\ProgramData\Anaconda3\lib\site-packages\neo4j\io\_bolt3.py", line 339, in fetch_message
response.on_failure(summary_metadata or {})
File "C:\ProgramData\Anaconda3\lib\site-packages\neo4j\io\_bolt3.py", line 536, in on_failure
raise Neo4jError.hydrate(**metadata)
neo4j.exceptions.TransientError: {code: Neo.TransientError.General.OutOfMemoryError} {message: There is not enough memory to perform the current task. Please try increasing 'dbms.memory.heap.max_size' in the neo4j configuration (normally in 'conf/neo4j.conf' or, if you you are using Neo4j Desktop, found through the user interface) or if you are running an embedded installation increase the heap by using '-Xmx' command line flag, and then restart the database.}
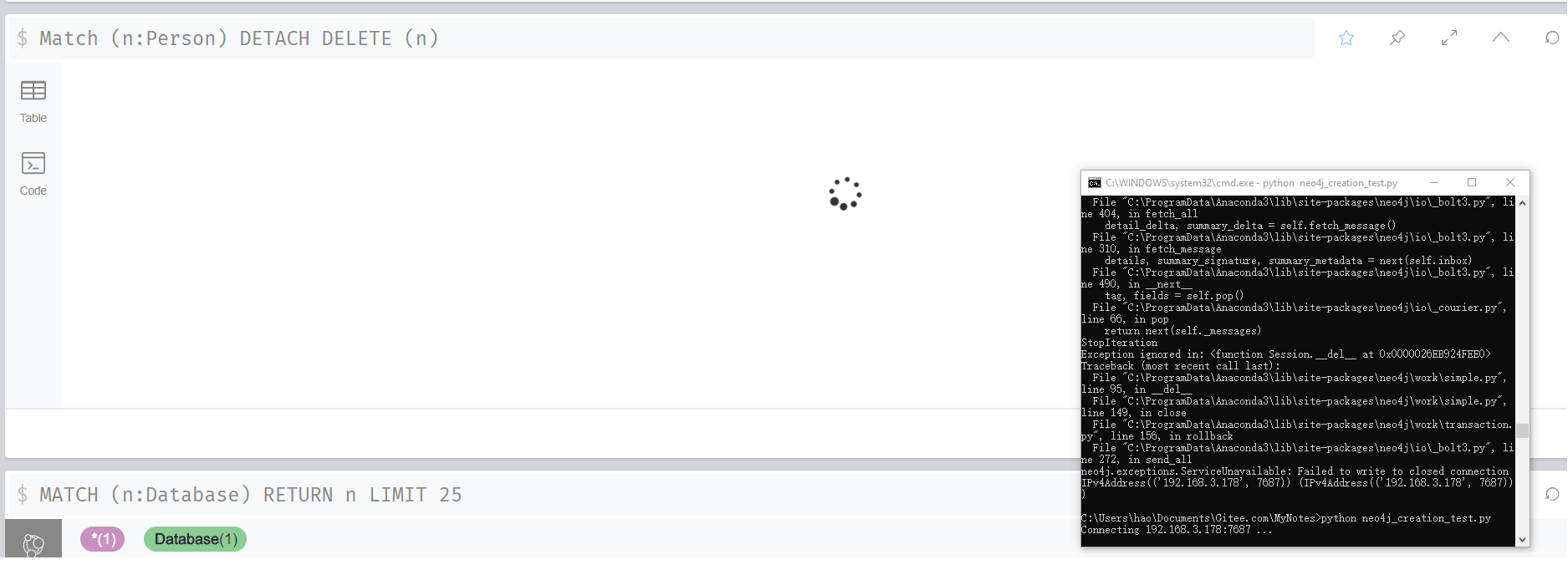
原因很显然是内存分配不足,所以只需增加分配的内存应该即可解决此问题。同时还发现,neo4j使用单线程,当长时间执行某任务时连接都会卡上,如下图所示。在网页上执行了 Match (n:Person) Detach Delete (n) 的操作还在进行中,但是此时命令行窗口进行连接就一直处于阻塞状态。
 )
)
3.2.3. 存储信息
| Store | Sizes |
|---|---|
| Count Store | 3.56 KiB |
| Label Store | 16.02 KiB |
| Index Store | 728.00 KiB |
| Schema Store | 8.01 KiB |
| Array Store | 8.01 KiB |
| Logical Log | 24.27 MiB |
| Node Store | 14.50 MiB |
| Property Store | 28.49 MiB |
| Relationship Store | 32.00 KiB |
| String Store | 8.01 KiB |
| Total Store Size | 318.06 MiB |
3.2.4. ID分配信息
| ID Allocation | Count |
|---|---|
| Node ID | 789522 |
| Property ID | 661657 |
| Relationship ID | 161 |
| Relationship Type ID | 19 |
3.3. 第3次实验 (成功)
cpu:2核 Intel(R) Xeon(R) Platinum 8163 CPU @ 2.50GHz 内存:8g 硬盘:100g
在增加了内容以后,在121主机上测试后终于完成了,速度曲线如下所示。
总用时33分钟,相当于每小时约90万条数据。

3.3.1. 存储信息
| Store | Sizes |
|---|---|
| Count Store | 320 B |
| Label Store | 16.02 KiB |
| Index Store | 328.00 KiB |
| Schema Store | 8.01 KiB |
| Array Store | 8.01 KiB |
| Logical Log | 119.08 MiB |
| Node Store | 7.16 MiB |
| Property Store | 39.12 MiB |
| Relationship Store | 16.04 KiB |
| String Store | 8.01 KiB |
| Total Store Size | 165.75 MiB |
3.3.2. ID 分配信息
| ID Allocation | Count |
|---|---|
| Node ID | 500020 |
| Property ID | 1000000 |
| Relationship ID | 0 |
| Relationship Type ID | 0 |
3.3.3. 配置信息
注:之前是使用的默认值,出错后改为以下内容: neo4j信息 (conf/neo4j.conf 35, 36和46行) dbms.memory.heap.initial_size=1024m 最小堆内存 dbms.memory.heap.max_size=6128m 最大堆内存 dbms.memory.pagecache.size=2048m 缓存内存
3.4. 一些执行结果
删除所有Person Match (n:Person) DELETE n Deleted 288350 nodes, completed after 5624 ms.
3.5. 测试代码
人名为随机生成,由于时间催促,生成的人名看上去不真实,2021/02/21从学校下载了7.1万名学生的姓名,根据统计数据,补充了一版见这里。
#coding:utf-8
# 1. 随机生成 50万个节点标签均为Person,包括 name, sex 和 age 三个属性
# 2. 随机生成 200万个关系,包括朋友,同事,同学和亲戚4种关系
from neo4j import GraphDatabase
import random
import time
surnames=list('李王张刘陈杨赵黄周吴徐孙胡朱高林何郭马罗梁宋郑谢韩唐冯于董萧程曹袁邓许傅沈曾彭吕苏卢蒋蔡贾丁魏薛叶阎余潘杜戴夏钟汪田任姜范方石姚谭廖邹熊金陆郝孔白崔康毛邱秦江史顾侯邵孟龙万段漕钱汤尹黎易常武乔贺赖龚文')
#gvnames= [chr(ch) for ch in range(0x5e00, 0x9fa6)] # 所有中国汉字
gvnames=list(set(list('朝鲜朝鲜人的姓名一般为姓一个字和名字两个字亦有不多姓一个字和名字一个字或姓两个字和名字两个字或一个字的朝鲜人的姓中金李朴郑尹崔刘洪申全赵韩等多越南越南十大姓陈胡袁姚虞田孙陆王以及车英国史密斯琼斯威廉斯独联体伊凡诺夫华西里叶夫彼德洛夫德国舒尔兹穆勒施密特荷兰德夫力斯德扬波尔西班牙迦西亚费郎德兹冈查列兹法国马丁勒法夫瑞贝纳美国史密斯詹森卡尔逊俄罗斯俄罗斯人姓有伊万诺夫伊万诺娃罗果等妇女姓名多以娃娅结尾妇女婚前用父亲的姓婚后多用丈夫的姓俄罗斯名字有伊万伊万诺维奇尼娜伊万诺夫娜伊里奇万尼亚瓦纽沙谢尔盖等日本常用姓四百来个尤以铃木佐藤田中山本渡边高桥小林中村伊藤斋藤十姓为最多澳大利亚男名詹姆斯约翰戴维丹尼尔迈克尔女子名珍妮玛丽莎拉凯瑟琳如此多的高频词汇让孩子们的名字无意间撞车那么当时家长们是如何绞尽脑汁给孩子取名仍然踩雷的呢市民李先生说给儿子取名青云九歌东君青云衣兮白霓裳举长矢兮射天狼红楼梦第七十回薛宝钗作诗曰好风凭借力送我上青云在问卷调查中不少网友表示给孩子取名时都十分慎重老一辈喜欢根据易经等年轻人则喜欢从古诗词中寻找灵感市民刘先生给女儿取名炜彤就是翻的四书五经邶风静女彤管有炜说怿女美彤红色炜光彩当然也有偷方式网络上有不少起名网站只需输入出生年月时辰就可自动生成姓名小编随意在起名网站输入了姓氏郑和出生年月分别生成了个男女孩姓名女孩子是郑映蝶郑韵婷郑犁颖男孩的名字则为郑章硕郑伟光郑俊玮')))
# print(len(surnames), len(gvnames))
def get_name():
name = surnames[random.randint(1, len(surnames)) - 1]
name += gvnames[random.randint(1, len(gvnames)) - 1]
if random.random() > 0.3:
name += gvnames[random.randint(1, len(gvnames)) - 1]
return name
# id, name, sex(m/f), age(1-100)
# with open('data.txt', 'w', encoding='utf-8') as f:
# f.write('{0},{1},{2},{3}\n'.format(id, name, sex, age))
# 运行1万次,每次插入50个节点,总计50万个节点
total_times = 10000
batch_count = 50
def create_nodes(tx, cql):
return tx.run(cql)
print('Connecting 192.168.3.178:7687 ...')
driver=GraphDatabase.driver('bolt://192.168.3.178:7687', auth=('neo4j', '123456'))
print('Connected. \nBegin transctions...')
f = open('log.txt', 'w') # 记录日志
try:
with driver.session() as session:
for runTimes in range(total_times):
persons=[]
for i in range(50):
id = runTimes * batch_count + i + 1
name = get_name()
sex = 'm' if random.random() > 0.47 else 'f'
age = int(random.random() * 100)
info = '(:Person{{id:{0},name:"{1}",sex:"{2}",age:{3}}})'.format(id, name, sex, age)
persons.append(info)
cql = 'CREATE ' + ','.join(persons)
start_time=time.time()
session.write_transaction(create_nodes, cql)
end_time=time.time()
total_time=end_time - start_time # 每次插入用时
speed = batch_count / total_time # 插入速度
info = time.strftime("%Y/%m/%d %H:%M:%S", time.localtime()) + ' {0:>5d}: {1:6.3f}s, {2:6.2f} nodes/s.'.format(runTimes, total_time, speed)
print(info)
f.write(info + "\n")
except:
pass
f.close()